Migrating Data from Redshift to ClickHouse
Related Content
Introduction
Amazon Redshift is a popular cloud data warehousing solution that is part of the Amazon Web Services offerings. This guide presents different approaches to migrating data from a Redshift instance to ClickHouse. We will cover three options:
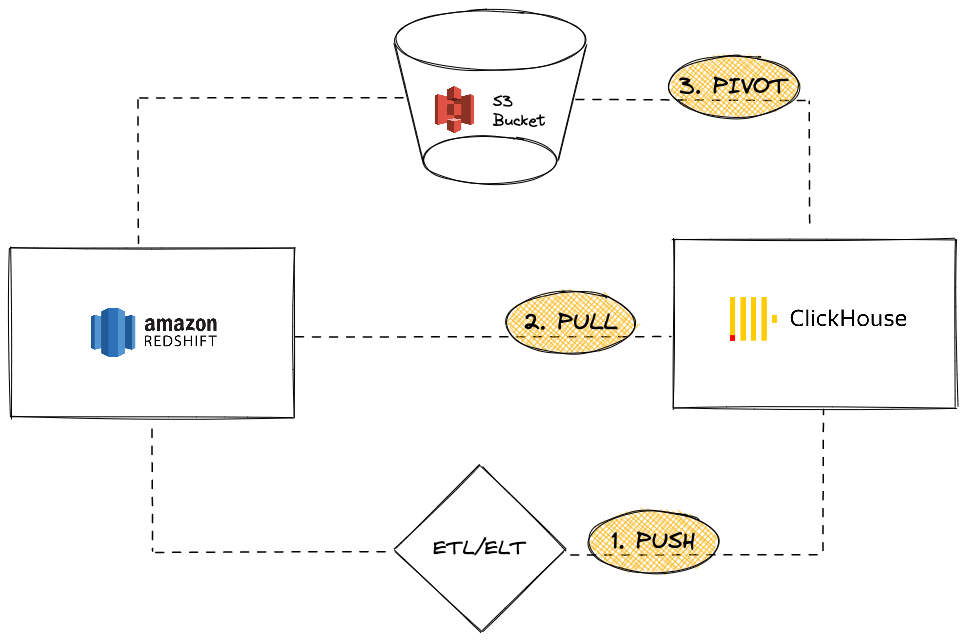
From the ClickHouse instance standpoint, you can either:
PUSH data to ClickHouse using a third party ETL/ELT tool or service
PULL data from Redshift leveraging the ClickHouse JDBC Bridge
PIVOT using S3 object storage using an "Unload then load" logic
We used Redshift as a data source in this tutorial. However, the migration approaches presented here are not exclusive to Redshift, and similar steps can be derived for any compatible data source.
Push Data from Redshift to ClickHouse
In the push scenario, the idea is to leverage a third-party tool or service (either custom code or an ETL/ELT) to send your data to your ClickHouse instance. For example, you can use a software like Airbyte to move data between your Redshift instance (as a source) and ClickHouse as a destination (see our integration guide for Airbyte)

Pros
- It can leverage the existing catalog of connectors from the ETL/ELT software.
- Built-in capabilities to keep data in sync (append/overwrite/increment logic).
- Enable data transformation scenarios (for example, see our integration guide for dbt).
Cons
- Users need to set up and maintain an ETL/ELT infrastructure.
- Introduces a third-party element in the architecture which can turn into a potential scalability bottleneck.
Pull Data from Redshift to ClickHouse
In the pull scenario, the idea is to leverage the ClickHouse JDBC Bridge to connect to a Redshift cluster directly from a ClickHouse instance and perform INSERT INTO ... SELECT queries:

Pros
- Generic to all JDBC compatible tools
- Elegant solution to allow querying multiple external datasources from within ClickHouse
Cons
- Requires a ClickHouse JDBC Bridge instance which can turn into a potential scalability bottleneck
Even though Redshift is based on PostgreSQL, using the ClickHouse PostgreSQL table function or table engine is not possible since ClickHouse requires PostgreSQL version 9 or above and the Redshift API is based on an earlier version (8.x).
Tutorial
To use this option, you need to set up a ClickHouse JDBC Bridge. ClickHouse JDBC Bridge is a standalone Java application that handles JDBC connectivity and acts as a proxy between the ClickHouse instance and the datasources. For this tutorial, we used a pre-populated Redshift instance with a sample database.
- Deploy the ClickHouse JDBC Bridge. For more details, see our user guide on JDBC for External Datasources
If you are using ClickHouse Cloud, you will need to run your ClickHouse JDBC Bridge on a separate environnment and connect to ClickHouse Cloud using the remoteSecure function
Configure your Redshift datasource for ClickHouse JDBC Bridge. For example,
/etc/clickhouse-jdbc-bridge/config/datasources/redshift.json{
"redshift-server": {
"aliases": [
"redshift"
],
"driverUrls": [
"https://s3.amazonaws.com/redshift-downloads/drivers/jdbc/2.1.0.4/redshift-jdbc42-2.1.0.4.jar"
],
"driverClassName": "com.amazon.redshift.jdbc.Driver",
"jdbcUrl": "jdbc:redshift://redshift-cluster-1.ckubnplpz1uv.us-east-1.redshift.amazonaws.com:5439/dev",
"username": "awsuser",
"password": "<password>",
"maximumPoolSize": 5
}
}Once ClickHouse JDBC Bridge deployed and running, you can start querying your Redshift instance from ClickHouse
SELECT *
FROM jdbc('redshift', 'select username, firstname, lastname from users limit 5')Query id: 1b7de211-c0f6-4117-86a2-276484f9f4c0
┌─username─┬─firstname─┬─lastname─┐
│ PGL08LJI │ Vladimir │ Humphrey │
│ XDZ38RDD │ Barry │ Roy │
│ AEB55QTM │ Reagan │ Hodge │
│ OWY35QYB │ Tamekah │ Juarez │
│ MSD36KVR │ Mufutau │ Watkins │
└──────────┴───────────┴──────────┘
5 rows in set. Elapsed: 0.438 sec.SELECT *
FROM jdbc('redshift', 'select count(*) from sales')Query id: 2d0f957c-8f4e-43b2-a66a-cc48cc96237b
┌──count─┐
│ 172456 │
└────────┘
1 rows in set. Elapsed: 0.304 sec.
In the following, we display importing data using an
INSERT INTO ... SELECTstatement# TABLE CREATION with 3 columns
CREATE TABLE users_imported
(
`username` String,
`firstname` String,
`lastname` String
)
ENGINE = MergeTree
ORDER BY firstnameQuery id: c7c4c44b-cdb2-49cf-b319-4e569976ab05
Ok.
0 rows in set. Elapsed: 0.233 sec.# IMPORTING DATA
INSERT INTO users_imported (*) SELECT *
FROM jdbc('redshift', 'select username, firstname, lastname from users')Query id: 9d3a688d-b45a-40f4-a7c7-97d93d7149f1
Ok.
0 rows in set. Elapsed: 4.498 sec. Processed 49.99 thousand rows, 2.49 MB (11.11 thousand rows/s., 554.27 KB/s.)
Pivot Data from Redshift to ClickHouse using S3
In this scenario, we export data to S3 in an intermediary pivot format and, in a second step, load the data from S3 into ClickHouse.
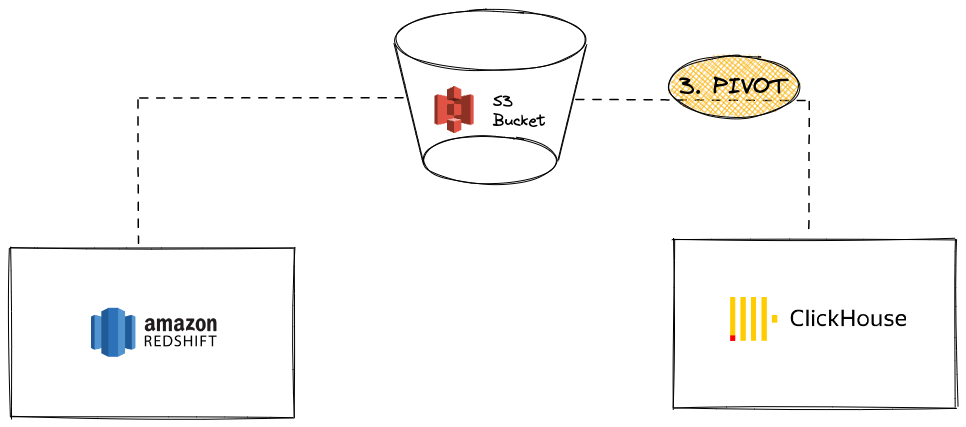
Pros
- Both Redshift and ClickHouse have powerful S3 integration features.
- Leverages the existing features such as the Redshift
UNLOADcommand and ClickHouse S3 table function / table engine. - Scales seamlessly thanks to parallel reads and high throughput capabilities from/to S3 in ClickHouse.
- Can leverage sophisticated and compressed formats like Apache Parquet.
Cons
- Two steps in the process (unload from Redshift then load into ClickHouse).
Tutorial
Using Redshift's UNLOAD feature, export the data into a an existing private S3 bucket:
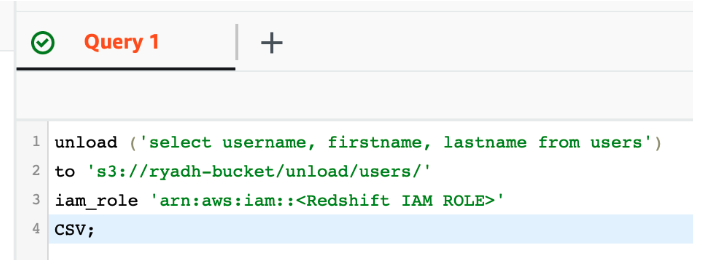
It will generate part files containing the raw data in S3

Create the table in ClickHouse:
CREATE TABLE users
(
username String,
firstname String,
lastname String
)
ENGINE = MergeTree
ORDER BY usernameAlternatively, ClickHouse can try to infer the table structure using
CREATE TABLE ... EMPTY AS SELECT:CREATE TABLE users
ENGINE = MergeTree ORDER BY username
EMPTY AS
SELECT * FROM s3('https://your-bucket.s3.amazonaws.com/unload/users/*', '<aws_access_key>', '<aws_secret_access_key>', 'CSV')This works especially well when the data is in a format that contains information about data types, like Parquet.
Load the S3 files into ClickHouse using an
INSERT INTO ... SELECTstatement:INSERT INTO users SELECT *
FROM s3('https://your-bucket.s3.amazonaws.com/unload/users/*', '<aws_access_key>', '<aws_secret_access_key>', 'CSV')Query id: 2e7e219a-6124-461c-8d75-e4f5002c8557
Ok.
0 rows in set. Elapsed: 0.545 sec. Processed 49.99 thousand rows, 2.34 MB (91.72 thousand rows/s., 4.30 MB/s.)
This example used CSV as the pivot format. However, for production workloads we recommend Apache Parquet as the best option for large migrations since it comes with compression and can save some storage costs while reducing transfer times. (By default, each row group is compressed using SNAPPY). ClickHouse also leverages Parquet's column orientation to speed up data ingestion.